
Hoe je betrouwbaar onderzoek kunt doen met virtuele patiënten
Voor elke patiënt het juiste geneesmiddel in de juiste dosering, dat is iets waar de medische wetenschap naar streeft. ‘Personalised medicine’ noem je dat. Maar er is veel onderzoek voor nodig met patiëntgegevens. En die liggen, onder andere door de privacywetgeving, niet voor het oprapen. Onderzoekers Laura Zwep en Coen van Hasselt, hebben hier iets op gevonden.
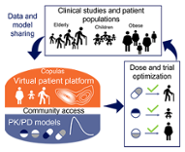
Zwep en Van Hasselt, beiden werkzaam bij het Leiden Academic Centre for Drug Research (LACDR), doen onderzoek naar het gebruik van statistische modellen genaamd copula’s. Nadat een copula-model is ‘getraind’ om individuele, privacygevoelige gegevens van de patiënten te beschrijven, kunnen er virtuele patiënten mee gemaakt worden. Onderzoekers kunnen de gegevens van deze ‘patiënten’ vervolgens vrij gebruiken en delen.
‘Met een copula kun je heel goed de verdeling én onderlinge samenhang van patiënteigenschappen beschrijven’, aldus Zwep en Van Hasselt. ‘Dit is van belang omdat er vaak complexe verbanden bestaan tussen eigenschappen zoals leeftijd en lichaamsgewicht, en bijvoorbeeld de functie van de lever, nieren en concentraties van allerlei moleculen in het bloed. Met een copula kunnen we deze relaties in kaart brengen, en vervolgens gebruiken om nieuwe virtuele patiënten te genereren.’
Datasets simuleren zonder beschermde patiëntgegevens
Om betere behandelmethoden te ontwikkelen is er dus eerst veel data van patiënten nodig. Hetzelfde medicijn heeft namelijk niet bij iedereen hetzelfde effect. Er is verschil tussen mannen en vrouwen, maar ook de ideale dosering verschilt per persoon. Dat heeft bijvoorbeeld te maken met leeftijd en lichaamsgewicht of andere kwalen. Trajecten om dergelijke informatie te verkrijgen bij ziekenhuizen zijn ingewikkeld, zeker als je er zelf niet werkt. Bovendien is het gebruik van deze gegevens aan veel regels gebonden. Onderzoek naar het optimaliseren van doseringen en het ontdekken van nieuwe verbanden zou veel sneller kunnen gaan als onderzoekers eenvoudiger toegang tot medische data zouden hebben.
‘Virtuele patiënten gedragen zich net zo complex als echte mensen.’
Met de nieuwe, virtuele gegevens van copula’s kunnen onderzoekers nieuwe datasets simuleren zonder dat daarvoor oorspronkelijke, beschermde patiëntgegevens nodig zijn. De echte data blijven netjes in het ziekenhuis, maar de zogenaamde ’waarschijnlijkheidsverdeling’ blijft hetzelfde. Met een copula kunnen onderzoekers systematisch aan de slag en de uitkomsten van de onderzoeken zijn identiek, omdat de virtuele gegevens statistisch exact hetzelfde zijn.’
Open science: maak zelf je virtuele patiënten
De Nederlandse Organisatie voor Wetenschappelijk Onderzoek (NWO) kende een Open Science-subsidie toe aan dit onderzoeksproject. Zwep en Van Hasselt willen hiermee ziekenhuizen trainen om hun databases om te zetten naar anonieme copula’s, die dan weer voor verder onderzoek te gebruiken zijn.
‘Met de beurs voor dit project kunnen we verder met het ontwikkelen van software en trainingsmaterialen om het gebruik van copula’s in een ‘open science’-omgeving mogelijk te maken. We willen ziekenhuizen en andere ‘gegevensbezitters’ trainen om op een eenvoudige manier zelf copula’s te maken waar anderen dan weer verder onderzoek mee kunnen doen. Door het creëren van oneindig veel virtuele patiënten die zich net zo complex gedragen als echte mensen, kunnen we samen de wetenschap weer een stap vooruithelpen.’
Tekst: Willemien Timmers
Afbeelding: Pexels